Real-life Semantic Web Technology-based Information Sharing via Linked Data Concepts – Redlink
My last post was the third in a series of “spotlight posts” I am using to illuminate practical examples of Real-life Semantic Web Technology-based Information Sharing via Linked Data Concepts. All of these examples support my proposed Enhanced Linked Data Architecture and its current incarnation as the Enhanced Linkeddata Architecture for Persistent Sharing Environments (ELAPSE)™.
My fourth post in this series is focused on Redlink, which:
“provides APIs to access the services of the (Redlink) platform. SDKs are available for major programming languages. Plugins are available for leading content management platforms such as Drupal, Alfresco, WordPress as well as for search engines like Apache Solr.”1
A short screencast for non-experts to set up their first Redlink App is available here.
Redlink’s tagline is:”We help you Make Sense of your Data.” They understand that, as organizations and users are creating an ever-increasing volume of content that is unstructured and lacks meaningful meta-data, manual tagging of this content with meta-data is impossible given the velocity and volume at which content is being generated. This limits the content’s find-ability, information discovery, and knowledge management–and, hence, decreases the value of content for business processes.
Redlink can help enterprises make sense of their data by semantically enriching, linking, and searching the vast amounts of unstructured data. This helps businesses to become more effective by managing actionable knowledge in the form of linked data instead of plain documents, content, or databases. They do this by exposing APIs in three different services areas of the platform:
1. Content Analysis – Redlink Content Analysis offers fact extraction, topic classification, content categorisation and fact linking from textual and media documents in different languages.
Content Analysis API documentation is available here.
2. Linked Data Publishing – Redlink Linked Data Publishing offers data management, data publication, and data integration for enterprise data using open standards and technologies (RDF and Linked Data). Legacy proprietary data can be transformed into a standardized data model and integrated with data from other sources.
Linked Data Publishing API documentation is available here.
3. Semantic Search – Redlink Semantic Search offers high performance faceted and semantic search over enterprise content, different ranking algorithms, auto completion, thesaurus/vocabulary integration, etc.
Semantic Search API documentation is available here.
Several demonstrations of developer platform access using these APIs are here.
There is also an SDK offering native integration of the Redlink services into the most common programming environments. A developer can simply configure the SDK with an API key and is then able to access the functionality without needing to explicitly call Web services. Currently, Redlink provides SDKs for Java, Python, PHP, and JavaScript.
More information is available here.
The Redlink Platform is attempting to turn semantic processing into a commodity by simplifying its use for web and application developers around the world without requiring the otherwise necessary technology expertise. Since the platform is implemented as a private cloud infrastructure, there is no need to install and configure complex technology. Instead, users can access the platform through the Internet, typically by calling Web services with an API key for identification, tracking, and billing. Even in small applications, like blogs or custom web applications, it is easy to use the technology. At the same time, the platform provides the scalability needed for large-scale applications with millions of documents. The platform is built on several existing open source framework architectures (e.g. Apache Stanbol, Apache Marmotta, Apache SOLR – links below), illustrated below:
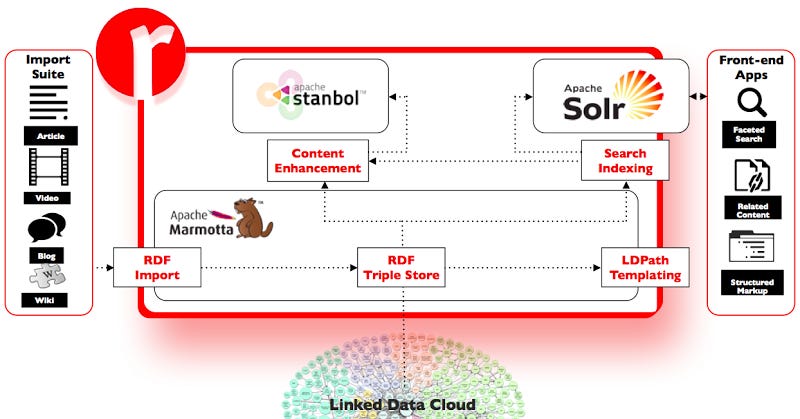
Redlink Platform Architecture
As with previous “spotlighted” projects, this solution has also attempted toaddress a number of the concerns, identified in my previous posts, that are commonly associated with today’s RDF Stores and Linkeddata Framework and Model solutions. This solution’s successful focus on creating a “Platform for Content Analysis, Linked Data and Semantic Search” will make this solution successful in the long run.
When focused on open source and open standards, this solution does implement a number of the same components (the Enhanced parts) of my Enhanced Linkeddata Architecture for Persistent Sharing Environments (ELAPSE)™, including:
My next post will discuss a fifth practical example of Real-life Semantic Web Technology-based Information Sharing via Linked Data Concepts.
=david.l.woolfenden